
はじめに
多くの研究者が、Gene Expression Omnibus (GEO)データベースで、興味のある研究に関連する特定のデータセットを検索しています。このデータセットは、多くの種類の二次研究や、開発・評価手法に利用することができます。例えば、GEOデータは、現在利用可能な解析プラットフォームの互換性を最大化し、解析アルゴリズムの有効性を比較するために使用されました (Eren et al., 2013; Golightly et al., 2018; Zhou et al., 2016)。GEOデータセットのその他の利用法には、発現量の異なる遺伝子の同定や疾患発症に影響する経路の同定など、複雑な生物学的プロセスや疾患に対する洞察を得ることが含まれます (Mecham et al., 2023)。
明確な基準があるにもかかわらず、多くの研究者がGEOデータベースで検索した結果、関連するデータセットは数件しか得られません。さらに、データセットをダウンロードし、関連するメタデータや注釈を抽出してデータ解析のために処理することは、時間がかかり、特にコンピュータスクリプトを作成するスキルのない研究者にとっては困難であることが判明しています。そこでこの記事では、二次解析のためのGEOデータセットの取得と統合に関連する課題と、Basepairの「Import data from GEO」パイプラインがこれらの課題を軽減するためにどのように使用できるかを説明します。
GEOの概要
2000年に発足したGEOは、National Library of Medicine (NLM) のNational Center for Biotechnology Information (NCBI)が支援するインターネットベースの一般公開データベースです。マイクロアレイ、次世代シーケンシング(NGS)、その他研究コミュニティから提出されたハイスループット機能ゲノミクスデータをアーカイブ化し、自由に配布するデータベースです。GEOで利用可能なデータの大半は遺伝子発現データであり、世界72カ国以上の研究者から提出されています (Clough & Barrett, 2016)。現在、GEOデータベースは6,000以上の生物にまたがる700万以上の生物サンプルのデータを保持しています (NCBI, 2024)。多くの論文や資金提供機関は、研究結果の検証を可能にし、データ資産へのアクセスを保証するために、GEO上でより広範なコミュニティとデータを共有することを研究者に求めています (Wilkinson et al., 2016)。
解析のためのGEOデータセット取得の課題
GEOのデータセットは、多様なデータタイプ、実験のバリエーション、メタデータの複雑さから複雑であると考えられています。この複雑さが、データアクセスや検索、統合、解析における課題につながる可能性があります (Mecham et al., 2023)。
データアクセスと取得
GEOからのデータアクセスと取得は、膨大な数のデータセットとNCBIインターフェースの複雑なメタデータにより困難な場合があります。GEOで関連データを効率的に探すには、検索戦略や検索基準のフィルタリングを慎重に検討する必要があります。データセットが選択されても、データセット上の注釈が欠落していると、データのダウンロードが困難になることがあります。関連する研究のすべてのデータセットをダウンロードし、データセットを相互検証する必要があるかもしれません。これには時間がかかり、バイオインフォマティクススキルのない研究者やNGSデータ解析の経験が浅い研究者には困難が伴います。
データの統合と解析
GEOに含まれる実験プラットフォーム、プロトコール、および生物学的システムの多様性を考慮すると、そのデータセットはしばしば、データの質や前処理方法において大きなばらつきがあります。このばらつきは、サンプル調製、ハイブリダイゼーション技術、バッチ効果、実験条件などの違いから生じます。さらに、一貫性のないメタデータ、不十分なメタデータの提出、GEOデータセット上の注釈の欠落などに起因するメタデータの複雑さも起こり得ます。異種のGEOデータセットとメタデータの複雑さは、結果的に解析ツールでのデータ統合を妨げ、特にバイオインフォマティクススキルのない研究者にとっては下流の解析を複雑にします。
Basepair上でのGEOデータセットの容易な取得と統合
二次解析のために複雑なGEOデータセットを検索し、解析ツールに統合することでもたらされる課題を軽減するために、Basepairは 「Import data from GEO」と呼ばれるパイプラインをプラットフォームに組み込み、二次解析のためのアプリケーションプログラミングインターフェース (Application programming interfaces (APIs)) を通じて、ユーザーが簡単にGEOから直接Basepairアカウントにデータセットをインポートできるようにしました。
このパイプラインのインプットは、解析したいデータセットのSRAアクセッション番号のみです。複数のデータセットを同時にBasepair上のプロジェクトにインポートすることができます。
GEOからBasepairにデータがインポートされると、データはユーザーのプロジェクトにサンプルとして保存されます。インポートされたサンプルの解析が実行されると、選択された解析パイプライン (例:Expression count (STAR) やDESeq2など) が解析実行に必要なメタデータやアノテーションを統合、抽出、処理します。
簡単なワークフロー
1. Basepairのアカウントにログインしてください。
2.「SAMPLES」をクリックしてください。
3.「Import from NCBI GEO/SRA」をクリックしてください。
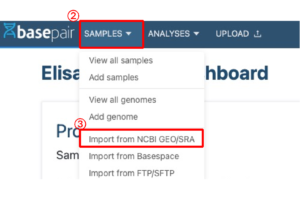
4.「Import data from GEO」パイプラインを選択してください。
5. パイプラインのバージョンを選択してください。(現在選択できるのは1.0のみ)
6. データのSRAサンプルアクセッションID (例:SRR1222684) を入力してください。
7.「Analysis name」は変更可能です。
8.「Run analysis」をクリックしてください。

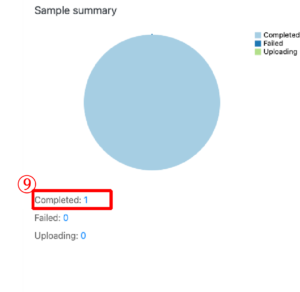
9. データのインポートが完了すると、サンプルはBasepair上のプロジェクトに保存されます。
参考文献
Clough, E., & Barrett, T. (2016). The Gene Expression Omnibus database. Methods in Molecular Biology, 1418, 93–110. https://doi.org/10.1007/978-1-4939-3578-9_5
Eren, K., Deveci, M., Küçüktunç, O., & Çatalyürek, Ü. V. (2013). A comparative analysis of biclustering algorithms for gene expression data. Briefings in Bioinformatics, 14(3), 279–292. https://doi.org/10.1093/bib/bbs032
Golightly, N. P., Bell, A., Bischoff, A. I., et al. (2018). Curated compendium of human transcriptional biomarker data. Scientific Data, 5, 180066. https://doi.org/10.1038/sdata.2018.66
Mecham, A., Stephenson, A., Quinteros, B. I., et al. (2023). TidyGEO: Preparing analysis-ready datasets from Gene Expression Omnibus. Journal of Integrative Bioinformatics, 21(1), 20230021. https://doi.org/10.1515/jib-2023-0021
National Center for Biotechnology Information (NCBI). (2024). Gene Expression Omnibus (GEO). https://www.ncbi.nlm.nih.gov/geo/summary/?type=series
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., et al. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18.
Zhou, W., Han, L., Altman, R. B. (2016). Imputing gene expression to maximize platform compatibility. Bioinformatics, 33(4), 522–528. https://doi.org/10.1093/bioinformatics/btw664.